

The AI Progress Paradox
Receding Horizons and Misleading Milestones

(This is a bit shorter than my usual posts. I’m anticipating a few more short posts, coming more frequently than usual, as I clear away some clutter along the path to an AGI timeline estimate.)
I’m in the middle of a series of posts in which I’m working toward an estimated timeline for AGI. I don’t yet know where that estimate will come out, but my time unit appears to be “decades”, not “years”.
In the current climate, it feels foolhardy to make such a conservative1 forecast. There’s such a rich recent history of confident predictions that “it will be a long time before AI can do X”, followed by AI doing X like three days later. Dario Amodei, CEO of Anthropic2, recently speculated that human-level AI “could happen in two or three years”. Concretely, Time Magazine published a chart showing that AI has been reaching or surpassing human skill across an increasing variety of tasks:

How to reconcile these unambiguous signs of unrelenting, rapid, accelerating progress, with a belief that true human-level AGI is still a ways off? I think the explanation is as follows: some problems – such as self-driving cars, curing cancer, and AGI – only reveal themselves gradually. We can’t appreciate the full scope of the task until we’ve solved some of the subtasks. As a result, progress toward the solution has the paradoxical effect of increasing our estimate of the problem. As AI knocks down challenges, from image recognition to essay writing to the freaking bar exam, our understanding of the full scope of “human-level AI” expands; the finish line appears to recede almost as quickly as our motion toward it. As I said in Beyond the Turing Test:
As we progress toward an answer to the question “can a machine be intelligent?”, we are learning as much about the question as we are about the answer.
Problems That Reveal Themselves Gradually
Certainly there have been past examples where a technology exhibited rapid progress, only for its full fruition to recede into the distance. Consider self-driving cars. There is a rich history of overly-optimistic predictions; here’s one compendium:
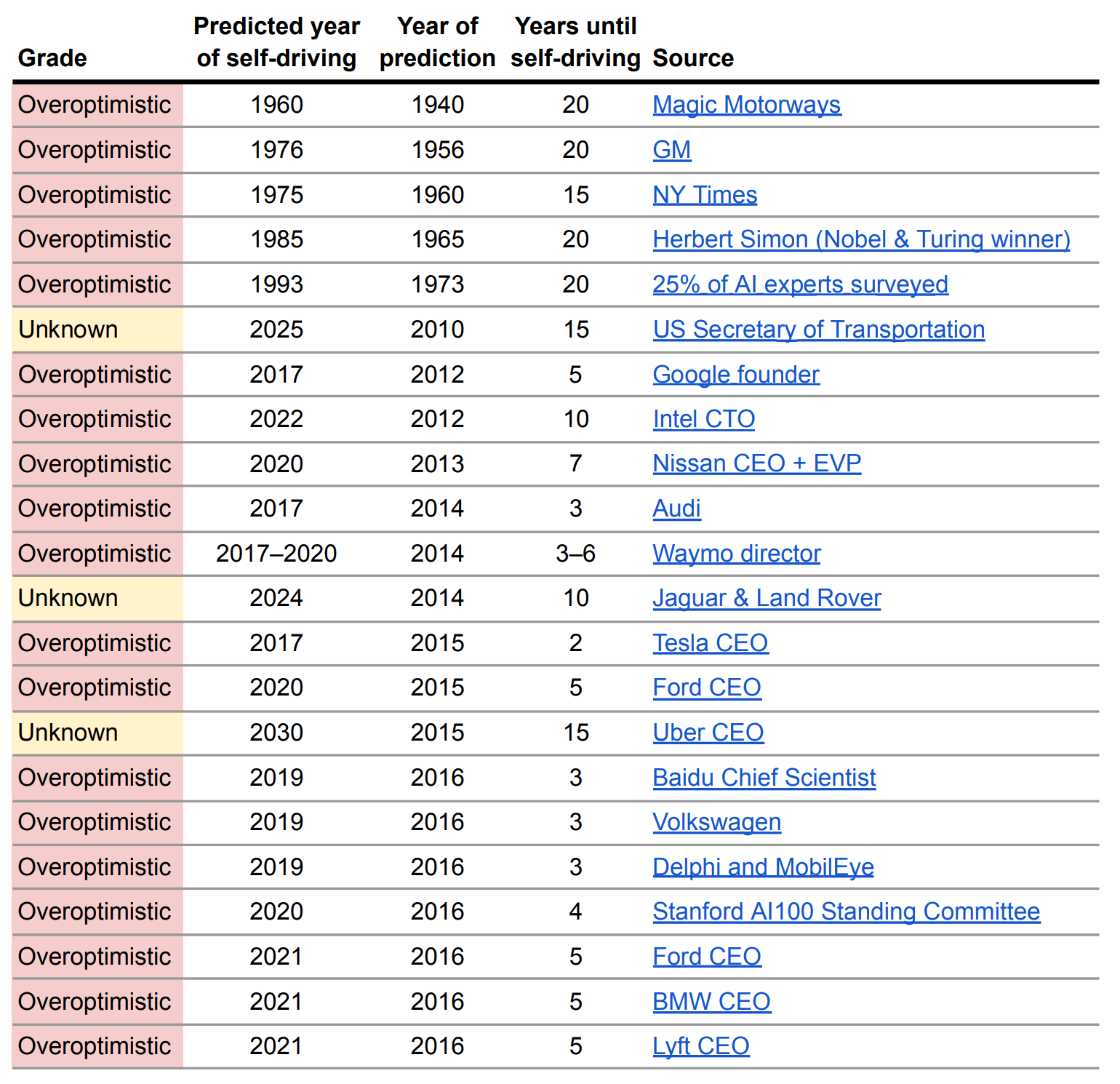
The consensus view at the moment is not particularly optimistic; many companies have dropped out of the race, and the remaining players, such as Waymo and Cruise, are moving cautiously.
My point is not just that self-driving cars are way behind schedule. My point is that they are delayed despite astounding progress. Waymo and Cruise vehicles have driven millions of miles with no one behind the wheel, under real-world conditions, successfully navigating many messy situations. And yet, 16 years after the promising results of the DARPA 2007 Urban Challenge kicked off the current multi-billion dollar race, self-driving cars are still not ready for prime time.
What’s the difficulty? Well, driving entails coping with an enormous variety of situations. Rain, snow, sleet, hail, fog. Potholes. Construction. Debris in the roadway. Police directing traffic. Fire hoses. Misbehaving pedestrians. Faded lane markings. A ball rolling down the street. Animals. Turns where you’ll wait forever unless you get aggressive. Black ice. Detours. The list goes on and on.
Most people kind of understood this from the beginning, but it’s impossible to grasp the sheer number of edge cases until you’re operating in the real world. For instance, I don’t know of anyone who anticipated that people would start placing traffic cones on the hoods of self-driving cars in a deliberate (and successful) attempt to confuse them. And there are increasing complaints of these cars blundering into fire scenes and other emergency-responder situations. And in the you-can’t-make-this-stuff-up department, there’s no topping this fresh report:
A Cruise spokesman, Drew Pusateri, confirmed that one of the company’s driverless vehicles had “entered a construction area and stopped in wet concrete.”
When I say that some problems reveal themselves only gradually, this is what I’m talking about. Until you can keep a car within its lane, you can’t get out on the roads and learn about the challenges posed by windblown trash. Until you’ve dealt with trash, you can’t accumulate enough miles to encounter emergency responders. The learning curve is necessarily sequential, and until you’ve dealt with the current crop of challenges, you’ll never know what further challenges might arise.
(Any programmer who has ever been “one more compile” away from finishing a project, only to find another bug, and another, and another, is familiar with this phenomenon.)
The fight to cure cancer can be viewed in the same way. First we needed drugs that could attack cancer cells. Then we found that drugs that worked for one patient didn't work for another. That led us to realize we didn't understand the problem well enough – cancer isn't a single disease, it's a crude label for all diseases with the common attribute of uncontrolled cell growth. The 50+ year history of the “War on Cancer” includes many rounds of this cycle, where each new solution bumps up against another layer of the problem. How to get drugs to specifically attack cancer cells and not healthy tissue? How can drugs reach the interior of a solid tumor? How to prevent tumors from mutating to evade a drug? And thus, while we have an array of cancer therapies that would seem miraculous to a researcher from the 1970s, cancer is still the #2 cause of death in the United States. We’ve built a big pile of solutions, but along the way we learned that the problem is even bigger.
Impressive Results That Don’t Generalize

A hallmark of these gradually-revealed problems is an impressive result that fails to generalize to the full problem domain. For instance, in the early days of computing, it was assumed that for a computer to play chess, it would have to have mastered “thinking”. After all, at the time, the only known example of entities that could play chess – i.e. people – were general-purpose intelligences. Then decent chess programs were constructed, using an approach that had very little to do with general intelligence. It was only in hindsight that we could recognize that computer chess didn’t imply the imminent arrival of AGI.
(This explains the “moving the goalposts” phenomenon: repeatedly redefining “AI” to exclude whatever new problem computers have just solved. By solving a problem, we reveal why that problem was distinct from human-level general AI; only by reaching the goal can we understand that the goal was incomplete.)
We’re now in a similar position with regard to the accomplishments of large language models. Quoting from Beyond the Turing Test again:
Five years ago, I think almost anyone would have said that acing the AP Bio exam would require substantial reasoning ability. Based on GPT-4’s performance, it now appears that it can also be done using shallow reasoning in conjunction with a ridiculously large base of knowledge. Who knew?
Apparently no one knew, until we built GPT-4, saw it happen, and were forced to move the goalposts yet again.
By solving a sub-problem (e.g. chess as a subproblem of thinking, or driving under ordinary conditions as a subproblem of driving), we reveal further aspects of the problem (fuzzy cognitive tasks that, unlike chess, don’t yield to a simple tree search over a finite list of moves; emergency responders cordoning off an area). Thus, gradually-revealed problems often exhibit impressive special-case solutions that don’t generalize to the full problem.
Progress Confined to A Single Subdomain
Remember the chart at the top of this post, showing AI matching human-level performance at one task after another? The tasks include things like “handwriting recognition”, “reading comprehension”, and “code generation”. These all have at least two properties in common:
They don’t require any contextual information. You could give these tasks to a new hire in their first 5 minutes on the job.
They don’t require any extended, creative, iterative thought processes, of the sort I described in Process vs. Product: Why We Are Not Yet On The Cusp Of AGI. They consist of independent subtasks that could plausibly be solved in a few minutes, in a single pass without backtracking, by an (appropriately qualified) person.
The same applies to passing the bar exam, summarizing a document, and the other sorts of challenges that language models are currently knocking down. The progress is impressive, but in some sense it’s just multiple examples of the same thing. If a tennis player wins the French Open, and then follows that up with victories at Wimbledon, the Australian Open, and the US Open, we are impressed, but we don’t ask whether they’ll soon be outdistancing cyclists at the Tour de France or getting signed to an NBA team. In the same fashion, when a model knocks down a series of contextless tasks that can be performed without iteration and revision, we should be impressed but we should not necessarily assume that it will soon be tackling other sorts of challenges, such as large-scale open-ended creative work.
(This is why I don’t expect straightforward further scaling of current LLMs, in the form that I believe many people anticipate when they talk of a hypothetical GPT-5, -6, or -7, will result in anything like AGI. For instance, I’m not aware of any argument that adding more neurons and training data to current LLM architectures will somehow give them long-term memory.)
Implications For AGI Timelines

I’ve argued that constructing an AGI is a task whose scope becomes visible only gradually. This distorts our view of the timeline: as we progress toward the goal, we discover new challenges, thus revealing past estimates to have been overly optimistic. Compounding this bias is the fact that the field is prone to impressive results that turn out not to generalize. Yet another source of excessive optimism comes from the fact that an apparent flurry of progress – such as the myriad applications currently emerging from LLMs – can turn out to be contained within a single subdomain, and thus effectively constitute multiple examples of a single accomplishment.
(This may explain the first half of Amara’s Law: “We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.”)
Given all of these sources of bias, how can we model future progress toward AGI? The best we can do is to maintain humility, and recognize that time estimates which extrapolate from current capabilities – ChatGPT can do college-level work, we must be nearly there! – are always likely to be optimistic.
At the same time, we should keep in mind that specific applications often turn out to not require full AGI – as we saw with chess and the AP Bio exam – and so we should always be prepared for particular tasks to be solved unexpectedly quickly. We should neither be complacent about having time to prepare for AI to reach any particular milestone, nor over-interpret such milestones as indicating the that full AGI is just around the corner.
This post benefited greatly from suggestions and feedback from David Glazer. All errors and bad takes are of course my own.
At least, conservative by the standards of the current hype cycle. “AGI appears to be only a few decades away” would have been seen as an aggressive prediction only a few years ago!
Hmmm so I've been mulling this too: LLMs for example do predictive modeling based on what is most likely to come next averaged across all the different training examples. They sometimes make stuff up and sometimes get things wrong. It's possible therefore to suggest that they have accurately modelled language but not modelled meaning. Because they don't have meaning modelled they are not "grounded" in either definitions or experience whereas humans are.
BUT... a counter argument is that the prompt is the grounding (which is why prompt engineering "works") and RHLF is the "experience". You can maybe take both of these together and have the situation that real soon now (less than 5 years) we have a sufficiently well trained LLM via RHLF that it responds just like a human would. Maybe... ha.